Say you’re hungry. Where’s the first place you look for food? The farm where it’s grown, the forest where you can forage for it, the supermarket or your own pantry and fridge first?
Unless you’re living in pre-industrial times, your decision looks something like this:

That last step is probably redundant in recent history but the main idea still stands. You don’t go straight to the ultimate source of food when you’re hungry. You look for the closest local link in your food supply chain (which is usually your own pantry/fridge) before moving up the chain if no food exists there.
The thing is, while we apply this process to food, we don’t apply it to our information/content diets. As software developers/engineers, this has far-reaching consequences to our productivity and mental health. We’re knowledge workers, so our consumption of information is as essential as food for us to survive and thrive.
That’s where the concept of a “second brain” comes in.
What is a second brain?
The phrase “second brain” was coined by productivity expert Tiago Forte. In his words:
Building a Second Brain is an integrated set of behaviors for turning incoming information into completed creative projects. Instead of endlessly optimizing yourself, trying to become a productivity machine that never deviates from the plan, it has you optimize an external system that is more reliable than you will ever be. This frees you to imagine, to wonder, to wander toward whatever makes you come alive here and now in the moment.
Essentially, a second brain is a personal knowledge management system that serves as an extension of your mind so you don’t have to think as hard or remember as much. You offload thinking and remembering to your private second brain.
Like Sherlock Holmes’ “mind palace”, it’s a place to store all of your lingering thoughts and curate the information you consume on a daily basis from books, the Internet and other sources so that you don’t get overwhelmed with unnecessary info and take action with the knowledge that matters.
Why build a second brain?
Most, if not all, software developers have a shot-gun approach to finding the information we need to solve issues or progress/learn new things. If we have a problem we need help with, we’ll usually follow a pseudo-supply chain that goes something like this:
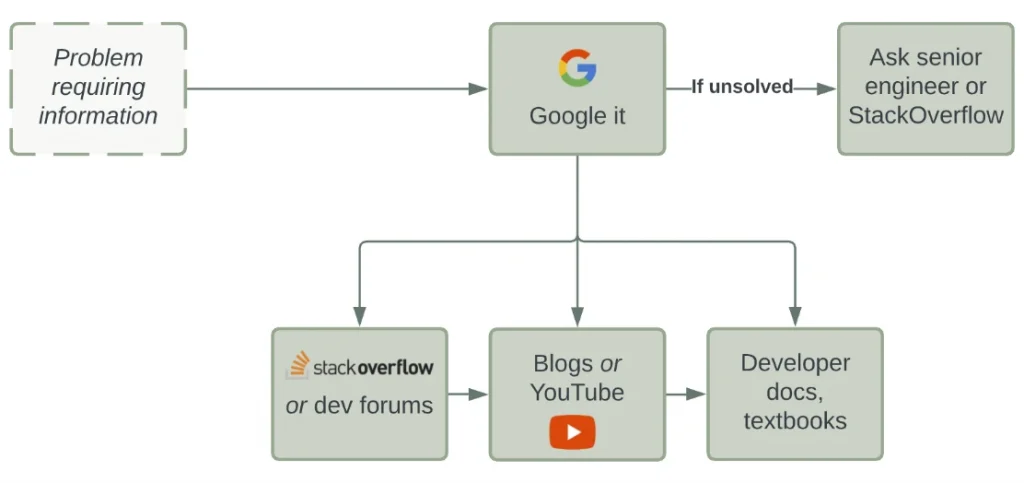
As you can probably tell, there’s no “local link” in this supply chain that we’ve developed. Google is the closest link, meaning we use the massive, unsorted network that is the Internet and Google’s interpretation of our problem as our “second brain”.
By scouring the massive Q&A databases of StackOverflow, the millions of videos and articles on YouTube and personal blogs or complex developer documentation, we forget one thing.
We’re going directly to the farm/forest every time we need food.
A “second brain” is the solution to this problem.
By building our own “second brain”, we can create our own local link in the information supply chain that holds relevant information optimised for our needs instead of relying on Google and scouring the Internet every time.
Let’s look at how you can build one.
How to build a second brain as a software developer
Step 1 – Choose an application
You need something to serve as the system that houses your second brain.
There are 15 qualities the ideal second brain system has as specified by Tiago Forte (the original creator of the second brain concept), split into deal breakers, must-haves and nice-to-haves:
Deal breakers
1. Quick capture and editing
2. Scales to thousands of notes without performance lag
3. Basic formatting options
4. Strong search feature
5. Ability to handle images and attachments
6. Private space, with public sharing
Must-haves
7. At least 3 levels of hierarchy
8. Many ways to capture information
9. Native and web versions
10. Capturing and syncing across multiple devices
11. Exportable as plain text
Nice-to-haves
12. Side-by-side viewing
13. Bullets or lists
14. Automatic date stamps
15. Tags
While it’s possible to use manual methods like a notebook or sticky notes, it’s difficult to scale these to thousands of notes, handle images and code snippets, allow portability for quick capture/editing and most importantly allow for searchability.
Hence why a digital system is essential (especially in the context of software development).
At time of writing, there are heaps of digital note-taking apps in the market. But, for the purposes of this article, I’m just going to list the ones that are most widely used as “second brains”/personal knowledge management systems:
- Notion
- Evernote
- Roam Research
- OneNote
- Honourable mentions: Workflowy, Obsidian, Supernotes
All of the listed apps meet the requirements needed for a second brain/personal knowledge management system. Each app works in different ways and has its benefits and drawbacks so pick the one that works best for you. Your second brain is for your eyes and use, not someone else’s.
If you use Notion, Obsidian or Evernote, you might be interested in Tressel – an app that seamlessly syncs your info from around the web (from places like Twitter and Reddit) to your note-taking apps
Related reading


Step 2 – Create a general-purpose structure/wireframe
Next, we need to structure our chosen application to allow us to capture, sort and retrieve relevant information efficiently. There’s two organisational systems that stand out here:
- Zettlekasten
- The PARA Method (recommended)
The Zettlekasten approach advocates for a disciplined approach to note-taking. Notes are captured “atomically” in the shortest and most modular manner possible. Once captured and split into components, you then search for other relevant notes you’ve taken in the past to link them to. Finally, you update your overall network of notes to make your recently captured note accessible. Having a network of notes is invaluable but it requires a lot of time and effort.
The PARA Method reduces the fatigue of information capture. There’s no linking needed. It involves simply splitting all information into four categories based on purpose and timely relevance:
- (Tasks) – info stored in Projects or in memory
- Projects – goals to be achieved with deadlines – info needed now
- Areas – standards/broad categories with no end date – info needed a bit later
- Resources – topics/themes of ongoing interest – info needed someday
- Archives – info that you won’t use for a while and doesn’t fit into the other three categories – info not really needed/held just-in-case
These categories are all nested. Tasks are nested under Projects which fall under Areas which fall under Resources, with Archives serving as the catch-all category.
Projects serve as your short-term memory and hold information you’ll likely need now/soon while the deeper you go (i.e. Areas → Resources → Archives), the later the information is needed.
It’s also a good idea to have an entrypoint (or Inbox) for all of your captured info before it’s sorted into one of the above categories.
Related reading


Step 3 – Create data structures for captured information
The above general-purpose wireframes describe where to position and sort information, but not how to describe information to meet our needs. We need to provide the right metadata in our captured information so that it can be easily organized and retrieved later.
This single article can never hope to encapsulate every single piece of information needed by every software developer. Still, here’s some examples of information most developers need and how they can effectively store it.
Q&As – building your own StackOverflow
Q&As are the most raw and direct form of information. Our search for information starts based on a question we’re looking to have answered or a problem we want solved. Q&As can typically be found on sites like StackOverflow or developer forums and online communities.
- Question – the question you had (not necessarily the question the source author had)
- Answer – the answer that helped you (if possible, rewrite the original answer to be more relevant to your original question)
- Tags – keywords to make this easily search-able in future
- Links/related reading – links to other useful information (keep your notes as lean as possible)
- (Date) – should be automatically captured by your note-taking app
Code snippets and boilerplates
Code snippets and boilerplates are extremely actionable and designed to be copy-pasted in specific contexts. When considering the data structure for these, note that code from one language and one context cannot necessarily be used in projects with a different language/context.
Also, unlike Q&As, code snippets can’t be easily searched for based on their text contents. That’s why it’s important to put all snippets in a general structure (like a Notion database or a table with filters) that allows you to search based on language, type and context. For example, you should be able to search for all your front-end JavaScript snippets with a styling context.
- Language – e.g. JavaScript, Python, Go
- Type – e.g. front-end, back-end, deployment/DevOps
- Context – create your own multi-select categories to further describe the purpose of the snippet e.g. is this to do with styling, making API calls, creating utility functions etc.
- (Description) – a text-based description of the snippet
- Snippet – the actual snippet/boilerplate (wrapped in code tags)
- (Dependencies) – link to any other code or packages that are relevant or that you need to use this snippet
Documentation templates
These are basically text snippets. Templates for every bit of documentation your project needs like READMEs, CONTRIBUTING files, code review processes or test plans should be stored here.
While these are text-based, searching for a specific document (like a README) is still not easy as it sounds. That’s why, like code snippets, it’s important to keep documentation templates in a general structure that’s able to be filtered.
- Type – e.g. front-end, back-end, deployment/DevOps
- Location – where does this template go? e.g. repository, project management, client
- Title – e.g. README, CONTRIBUTING, QA plan
- Template – the actual template
- (Description) – a text-based description of the snippet
Resources
Resources are the least actionable, but most educative forms of information. They are the videos, courses, tutorials (and more) that you look for when you want to learn more about a broad area rather than fix a specific issue.
For instance, if you wanted to learn about Python, you’d save the best Python learning resources (i.e. tutorials, videos, articles and courses) you’ve come across in your second brain. This way, if you ever want to learn about Python in the future, you don’t have to repeat your search.
Since resources are your version of longer-term memory, you have to put some effort into making them easily retrievable in future.
- Name – a search-optimized name of the resource
- Author – the original author of the resource
- Category – e.g. video, article, book, tweet, course, website
- URL – where can you access this resource (note – you don’t want the entire resource in your database, you just want a link to minimise bloat)
- Status – have you completed reviewing this resource?
- Tags – keywords not in the name to make this easily search-able in future
- (Rating) – how effective this resource is at solving your problem or teaching you something
Step 4 – Determine your information workflows
The priority now is figuring out:
- How you’ll approach finding the information you need to solve problems
- How information will be sorted once it arrives into your second brain
Finding info
This is the part where you add your second brain to your information supply chain. Instead of going directly to Google when you have a particular issue, you now go to your second brain first.
Since we’ve neatly organised our content based on its purpose, relevance and timeliness, here’s our workflow for finding the information we need to solve problems we come across:
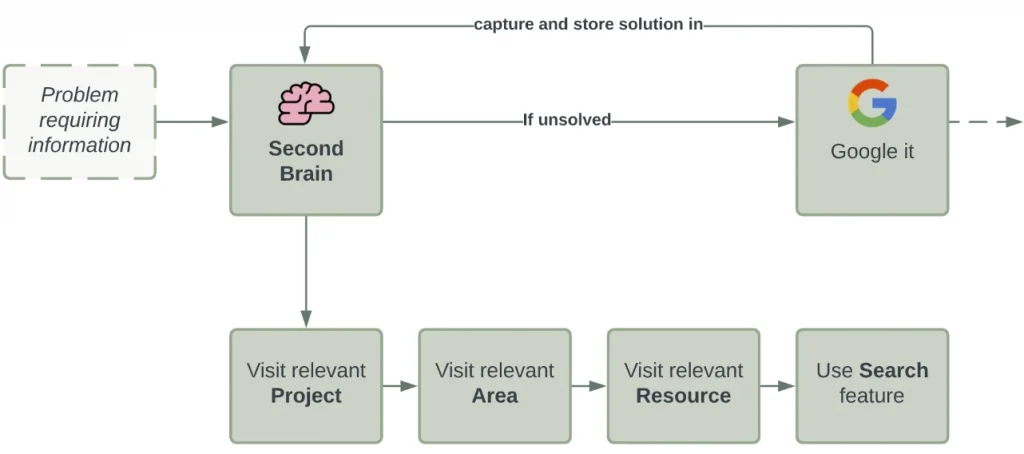
Sorting info
Ideally, you’ll have an inbox section where all incoming captured info is preliminarily stored. From here, it needs to be sorted into the appropriate category (based on the PARA method).
Depending on how relevant and timely it is, it needs to go into the appropriate project, area or resource umbrella.

For instance, if you’re currently working on a MERN stack project, then a code snippet on “How to set up MongoDB with Express” is very relevant and should go in the appropriate Project section. On the other hand, a tutorial on “How to create a REST API with Django” is less relevant and might go in the Resources section for future use.
You’ll ideally want to sort daily to review your incoming information and prevent information overload.
Related reading
Summary – flowchart
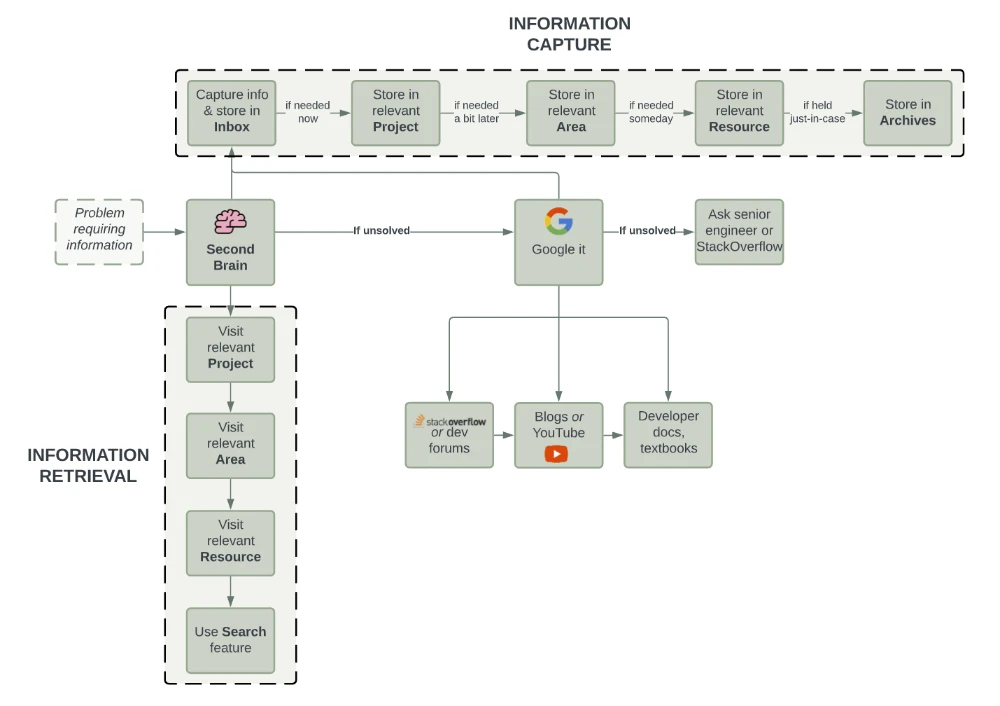
This is by no means a comprehensive guide. I fully acknowledge that I may have missed out on a lot of information you need to get a well-oiled second brain system working. For a more complete, general-purpose guide on how to build a second brain, check out Tiago Forte’s course. He’s far more of an authority on personal knowledge management/second brain systems than I am.
My main goal with this article was to show all developers that the shot-gun approach of Googling every single problem they come across is inefficient and unproductive. I hope I accomplished that and showed you a better way of doing things.
Further reading

